Generative Expert Metric System (GEMS)
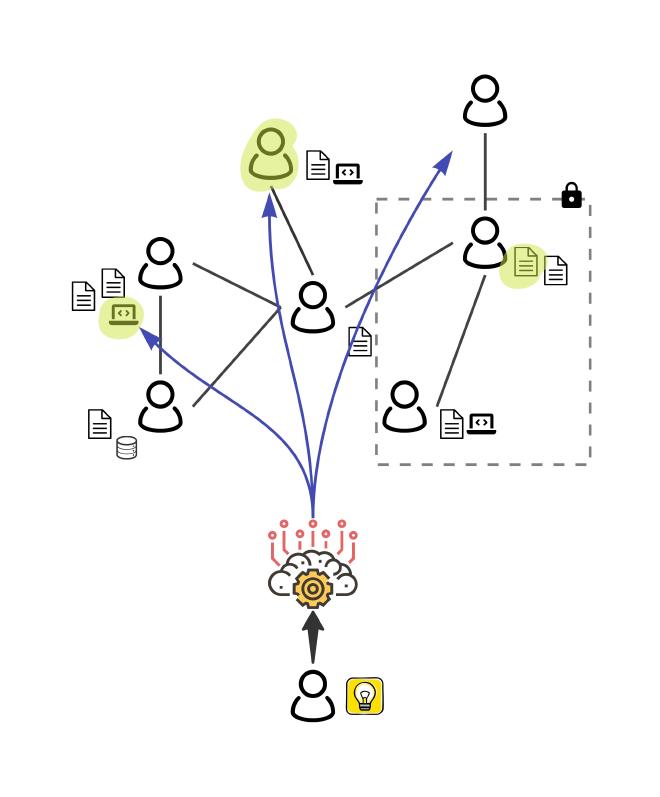
Table of Contents
At a Glance #
GEMS builds expert-grounded metrics for complex goals by orchestrating a panel of primed expert agents, a Programmer that operationalizes proxies using DevOps data, and a Judge that aggregates results. Against a vanilla “just prompt the model” baseline, GEMS generated more diverse, more specific, and more theory-grounded metrics. In a 10-goal comparison, the top-5 repeated metrics in the vanilla baseline covered 34% of all 178 metrics, while GEMS’s top-5 covered 10.11% of 180. This difference demonstrated broader exploration and more tailed metrics, which are critical in decision making scenarios.
I led the work end-to-end: architecture → prompt system → implementation → comparative evaluation in 2023, the year when GPT-4 was released with very limited API access.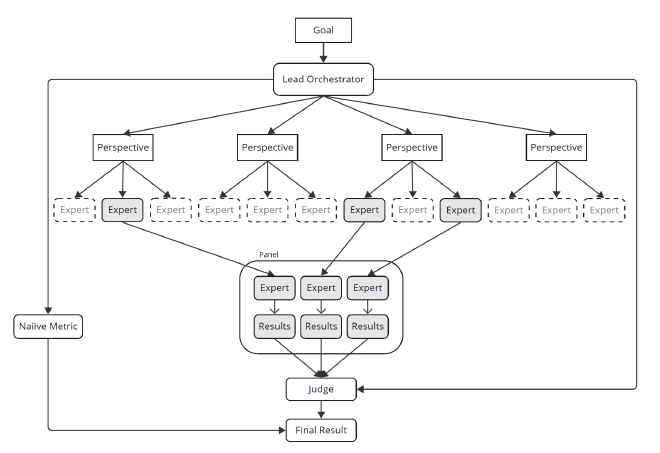
Why GEMS should Exist #
In large coorperations, expert finding and tacit knowledge are critical for productivity, innovation, and prevent wasted resources. Direct prompting with LLMs while produces metrics, often regresses to generic counters especially when the goal is complex or the executor is not an expert. For software engineering teams, common metrics include velocity, code churn, and issue counts can mislead triage and selection. GEMS addresses this by eliciting theory-informed metrics from multiple disciplines, turning “what should we measure?” into concrete proxies and documented rationales that can be automated.
How GEMS works #
Mechanism. GEMS is a multi-agent system:
- Lead Orchestrator: captures the goal, proposes a naïve main metric for initial targeting, and assembles an expert panel across relevant disciplines.
- Programmer: maps metric ideas to real data—selects or writes query functions, retrieves values, and, when possible, autogenerates code to compute the metric.
- Expert Agents (panel): use iterative prompt priming to (1) surface domain knowledge, (2) select relevant elements for the goal, and (3) design metrics that can be computed on the available data.
- Judge: chooses a decision mechanism (e.g., approval voting) and aggregates panel rankings with an auditable explanation.
Implementation. Orchestrated with AutoGen, Guidance, OpenAI API, and a MySQL datastore populated from OSS repositories (code, commits, PRs/issues, discussions). This setup makes the system replicable and minimizes privacy risk while preserving realism.
What I Did #
I designed the iterative priming stages, defined panel formation and discipline coverage, authored/rationalized/engineered the prompt pipelines, implemented the Programmer and Judge patterns, and ran the comparative evaluation. I also documented failure modes (over-specific metrics, assumptions about unavailable data) and set human-in-the-loop gates for deployment.
Who Should Care #
- Applied-AI / product analytics teams choosing metrics for triage, selection, or model evaluations.
- Engineering managers who need explainable metrics that match their goals and constraints.
- Researchers working on agentic evaluation and rubric construction.
Evaluation #
Two questions: What does GEMS generate compared to vanilla prompting? And how usable is the result for team matching and triage?
Setup #
- 10 goals (abstract + complex forms), all evaluated on the same dataset.
- Panel parameters: 4 disciplines → 3 experts total (2+1 composition); 3 metrics per expert → 9 metrics per goal.
- Baseline: GPT-4, no prompt engineering (“vanilla”).
- Analysis: extract metric names+descriptions, compare diversity, specificity to goal/theory, and operationalizability.
Findings #
1) Complexity & composition. GEMS often outputs composite metrics (e.g., userEngagement aggregating comments/reviews/reactions per user over time) versus single counters like numberOfContributors. Composition compresses multiple perspectives into one decision signal.
2) Specificity grounded in theory. Primed experts produce goal-specific metrics (e.g., refactoringFrequency for agility; recognitionRatio for social/affective collaboration), while vanilla regresses to generic “activity” measures. This improves face validity and auditability.
3) Operationalization trade-offs. Some GEMS metrics (e.g., calculateEconomicImpact, measureAutonomy) require assumptions or extra data beyond repos. They are valuable blueprints, but you must confirm data availability or define proxies.
4) Diversity. Vanilla’s top-5 metrics account for 34% of all outputs (178 total). GEMS’s top-5 account for 10.11% (180 total). This spread reduces metric monoculture and exposes alternatives worth piloting.
5) End-to-end auto-implementation (case). For a “keep projects on-track” goal, the Programmer auto-generated code for all 9 metrics and executed them against the database, completing a team-matching loop—evidence that the pattern scales beyond paper.
Decisions and Guidance #
Use GEMS to design and gate metrics for decision workflows. Ship with a Judge that explains the chosen aggregation, and require human approval before deployment. Avoid ungated, one-shot prompt scoring. For metrics that assume unavailable data, insist on proxy design or drop them from automation until data exists.
Limitations and Risks #
GEMS can over-specify or over-assume, and sometimes treat outputs as expert blueprints, not ground truth. Consider data privacy and access constraints, GEMs was not able to experiment on real company data. Since GPT-5 is not yet available, it is unclear how well the approach scales and compares to existing agentic systems.
What’s Next #
- Decision-quality study: teams using GEMS-designed metrics vs. vanilla prompts on real triage/selection.
- Evaluator UX: bundle metrics, preview trade-offs, and show Judge traces.
- Auto-calibration and drift detection for rubric evolution; better integration with internal knowledge bases and experts.